Understanding the Current State of Reasoning with LLMs
The goal of this article is to go through the repos of Awesome-LLM-Reasoning and Awesome-LLM-reasoning for an understanding of the current state of LLMs for logic.
I also presented this to Huggingface Reading Group so if you like videos instead, feel free to checkout here!
I will first go through the beginning of “Natural Language Reasoning, A Survey” as this was one of the only survey papers I could find that was published after GPT 4 was announced on March 14, 2023! But I will mainly cover just the initial parts. Then I’ll move on to various interesting papers in each repository/some papers I was interested in. I tried following a flow but I think I’ll organize this later if I get time.
Natural Language Reasoning, A Survey

In the image, PLM means Pretrained Language Models(thanks Jeff Berkowitz!)
Now first of all, what is reasoning? The paper argues there doesn’t seem to be a clear definition for reasoning in past research. For example, “name something you might forget in a hotel room” is commonsense reasoning but is not logical reasoning.
So the authors came up with the following definitions by combining philosophy and NLP:

so essentially, there needs to be some sort of processing on the knowledge we already have to make it reasoning like

Here is an example of what is reasoning and what is not

So essentially what I got is we can’t just rephrase what the premise says. We have to have a conclusion that uses at least 2 premises at once for it to be reasoning.
Now, this does make sense but while reasoning is almost well-defined, the “inference” part is not. What exactly is inference?
Inference
The paper defines 3 types of reasoning.
- Deduction = uses a fact and a rule to come up with a conclusion. Ex. Given Aristotle is a human and all humans will die, Aristotle will die
- Abduction=infer the best explanation for a given phenomenon. So given Aristotle is a human, and Aristotle died, the most likely explanation is all humans will die
- Induction=Formally this is defined as “An inductive inference is to infer probable knowledge, which describes a more general rule, extrapolated from the given knowledge.” I wasn’t sure what the difference between this and abduction was but this reddit post helped explain the difference as
“Hume’s argument that it is only via inductive reasoning that we believe the sun will rise tomorrow. Induction can guide us to the belief that the sun will rise tomorrow because it has risen for thousands of days in a row in our own lives and millions before (if testimony is reliable). It is via abduction that we would begin to suppose that the earth revolves around the sun (or perhaps the other way around) as an explanation for why the sun rises.”
So my understanding is abduction is a generalization of induction.
Both abduction and induction are called defeasible inference while deduction is called deductive inference. The author argues defeasible inferences are significantly less studied in current papers as opposed to deductive inferences.
Deductive and Defeasible Inference
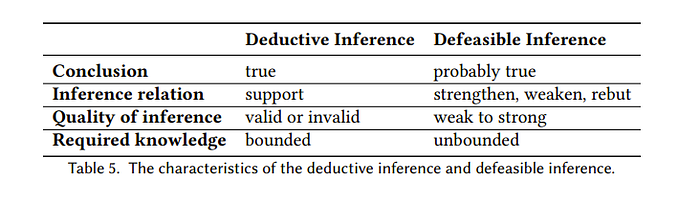
I discussed this in my literature review of AI in Law but the main difference between deductive and defeasible inference is while deduction comes up with conclusions that are always true, defeasible inference comes up with intermediate conclusions that may be true. For example, mathematics is a field that is purely working on deduction while law is a field where every argument/conclusion is defeasible, in that one counterargument can nullify any conclusion. An example of defeasible inference can be found here with tweedy bird.
Now, in general, why do we even do natural language reasoning? Can’t we restrict the domain to just formal language and prove it as we go along?
The issue is yes this will work with classic deduction-based logic but not with defeasible logic. I think this is because, as I mentioned in the literature review of law blog, it is computationally infeasible to verify defeasible logic which is also called non-nomonotonic logic.
However, the challenge of natural language for reasoning is, obviously ambiguity but also each word can refer to pretty much any other word in the whole text which this paper calls “many-to-many” while in formal logic it’s like knowledge graphs and is just triplets.
Secondly, data for natural language reasoning is hard to obtain. At least in the case of law, the court documents are paywalled unless you go to a non-profit that shares which however was only able to share a subset.
So given this, what will be the requirements for natural language reasoning
Requirements for Natural Language Reasoning
- Multiple knowledge. I think this means premises on which reasoning happens
- An algorithm capable of understanding and inference.
For this algorithm, the authors specify the exact steps it must follow as
- knowledge acquisition where relevant knowledge for reasoning is collected.
- knowledge understanding where the relevant propositions underlying the knowledge are captured.
- Inference which we already discussed where the premises are used to infer a conclusion given one or more steps.
Now then what are the advantages of using LLMs for NLP?
Advantage of LLMs
- LLMs understand natural language.
- LLMs already have implicit knowledge like common sense without needing to mention them explicitly
- In context learning. LLMs can learn from demonstrations in the prompt.
The final point the paper mentions is “Emergent Abilities” which was first introduced in “Emergent Abilities of Large Language Models”. As stated by the original authors, an “ability is emergent if it is not present in smaller models but is present in larger models.” Here these abilities are said to be “unpredictable” in that they are not a natural extension of say scaling laws.
Emergent Abilities of Large Language Models
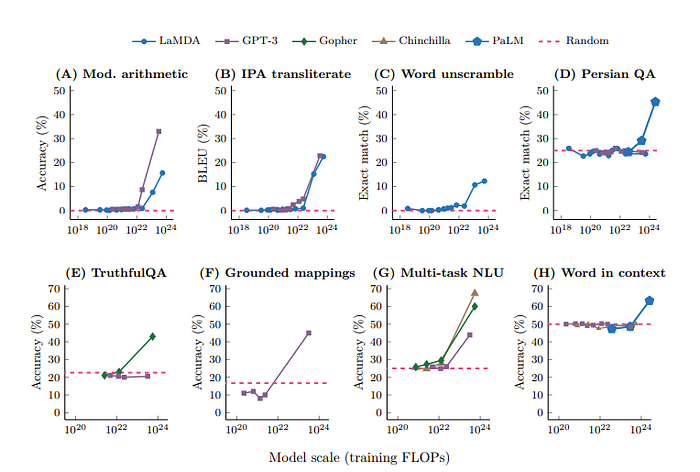
The first task the authors found demonstrating emergent abilities is few-shot prompting which is basically in context learning.
For this, the authors got datasets such as
- Big-Bench which is crowd sourced benchmark with over 200 types of benchmarks such as 3-digit addition/subtraction. For this dataset, at least 13B parameters for GPT-3 architectures and 68B for LaMDA was needed where otherwise the results were close to 0.
- TruthfulQA which are question and answers that GPT-3 failed to answer the authors found that after scaling to 280B params performance increases by 20% while before that the results were close to random.
- MMLU which is probably the most famous task here, is a task of 57 tests with topics including math, history, law etc. For models with below 10B parameters, they do not perform better than random. However, at 70B and higher the performance is substantially better than random.
More Advanced Prompting
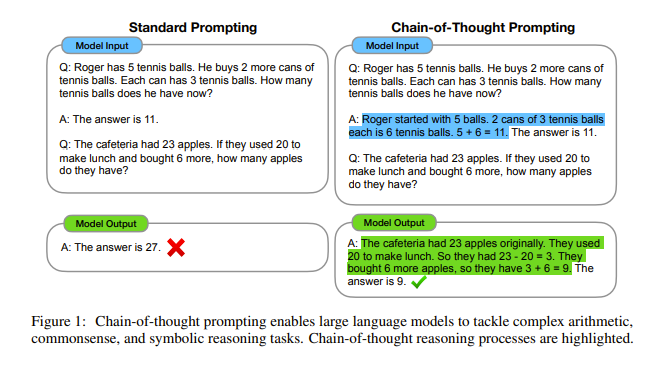
Now, there are more interesting prompting techniques than just in-context learning. For example, “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models” introduced a method of making models think of each step while doing in context learning
“Show Your Work: Scratchpads for Intermediate Computation with Language Models” introduced a method to do multi-step computation like adding 3 digit numbers/executing programs by having a scratchpad. This is pretty similar to chain of thought but a bit more concrete in that the intermediate states have a defined structure. For example,
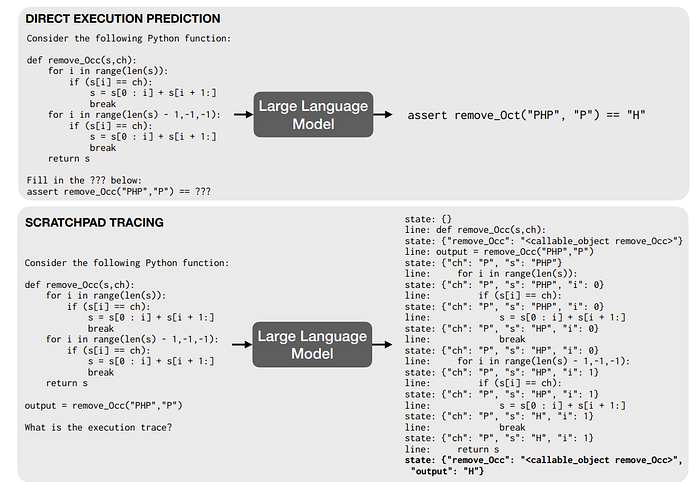
or in arithmetic
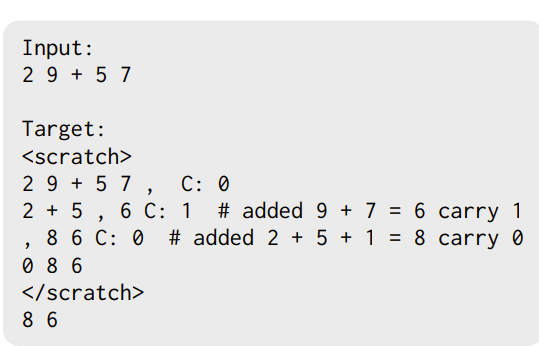
another difference here is the authors trained the models to use this scratchpad. However, the main observation they had was this allows the model to do different amount of computation for different models which is a huge advantage over direct prompting.
The final more advanced technique we will be discussing here is “Language Models (Mostly) Know What They Know” by Anthropic. This paper was Anthropics attempt to do something like having the LLM output the answer along with the confidence the model has for the answer. As I think this is interesting I will dedicate a section to it.
Language Models (Mostly) Know What They Know
This paper seems to build a lot on “Teaching models to express their uncertainty in words”.
Teaching models to express their uncertainty in words
The authors of the teaching models paper noted that we can get the certainty level of the next token just by looking at the probability distribution of the tokens. However, let’s say we generate a whole sentence. How do we then evaluate the certainty of this sentence? One idea is getting the probability of generating that said sequence but different tokens can lead to the same sentence and also this can’t be used for say OpenAI where we don’t have log probs.
So what the authors did was after the answer, they just verbally asked the model for confidence in the answer and then evaluated if the model said it was “90% certain” if it was actually correct 90% of the time.
Then the authors finetuned GPT-3 on the objective of predicted accuracy — predicted confidence from verbal output like so
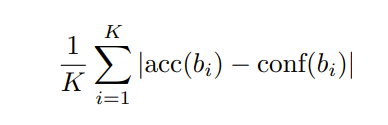
and they found this method outperformed all the log prob-based methods in the in-distribution data but for out-of-distribution, it became too unconfident.
Back to Language Models (Mostly) Know What They Know

This paper first found that prompt design is very important for calibration. In particular, when benchmarking with multiple choice questions like from MMLU,
- Replacing an Option with ‘None of the Above’ Harms Performance and Calibration
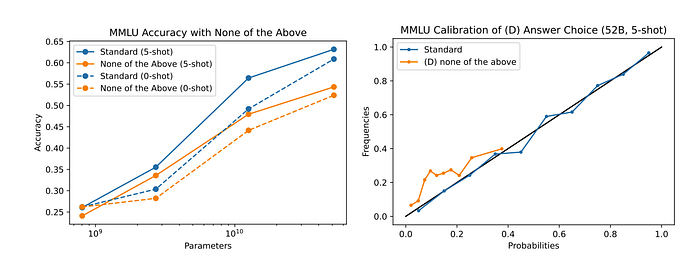
Here the left graph is a graph of the accuracy of the standard and none-of-the-above options and not having none-of-the-above consistently gives better results. The right one is a confidence vs accuracy/frequency metric. So with none of the above, the model is consistently less confident but accurate compared to the confidence. However, the standard options are already “well-calibrated” in that the confidence and accuracy align very well.
2. Models are well calibrated for True/False when asked in the format
Question: Who was the first president of the United States?
Proposed Answer: George Washington
Is the proposed answer: (A) True (B) False
The proposed answer is:One slight point I want to mention is if we don’t have A and B and instead have the model output True and False directly, I noticed a lot of models prefer outputting positive statements which causes True to overdominate the output. But this is a clever way of avoiding that issue.
3. RLHF Policy Miscalibration Can Be Remediated with a Temperature Tuning
Another interesting part of this paper was they found that, predictably when RLHF happens, the authors said it “tends to collapse language model predictions towards behaviors that receive the most reward” which I think means the model becomes way more overconfident. But interestingly, the authors found that using 2.5 as the temperature fixes this. I have no idea why.
Now, the paper does go on and it does tackle some more interesting details like what happens to confidence if we have a relevant context. One thing I am curious is what happens to the calibration curve given incorrect information in the context.
But I think I will go back to the original emergent ability paper to stay on topic.
Back to Emergent Abilities of Large Language Models
Now what the authors found, in pretty much all the papers above, is that this capability to understand these prompt instructions to improve the answer only occurs after a certain model size. (In the case of the previous paper the calibrated T/F prompt was used to my understanding)
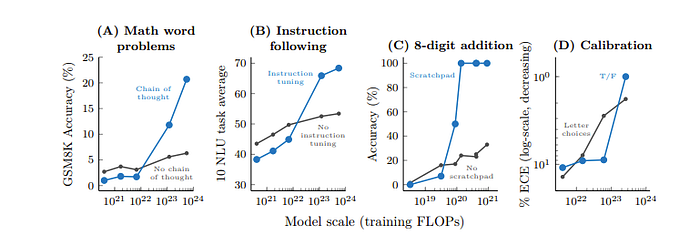
For example, in Multi-step reasoning like Math word problems, the usage of the chain of thoughts surpasses normal prompting at around 100B parameters and keeps gaining accuracy at a high rate.
The paper briefly mentions that there are some counterexamples. For example, when GPT-3 was scaled to 175B parameters, it failed to gain any emergent abilities. From what I understand, the authors claim that just scaling more would have unlocked emergent abilities “scaling PaLM …. from … 62B parameters … to …. 540B parameters… led to a significant jump in performance”
Now why does this emergence happen?
Potential explanations for the emergence
The authors suggested
- For l-step sequential computation, for example, chain of thought, the model may want a depth of at least O(l)
- Better memorization of world knowledge due to more parameters
- One hypothesis the authors had was because there was no partial credit assigned but the authors argued that prior to emergence the intermediate steps were at best random. Even for cross-entropy loss, which is the default loss of llms, the authors notice the emergence
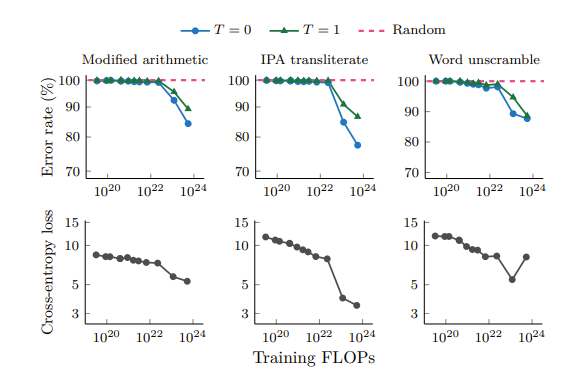
I think one puzzle piece missing is that large LLMs seem to have a better understanding of the context and forget less but I’m curious if there is research on this.
Now, back to the survey paper, I wasn’t able to find many cool definitive conclusions on the best approaches apart from the chain of thought being unreasonably good so next I want to explore some of the improvements on the Chain of Thoughts starting with “Tree of Thoughts: Deliberate Problem Solving with Large Language Models”
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
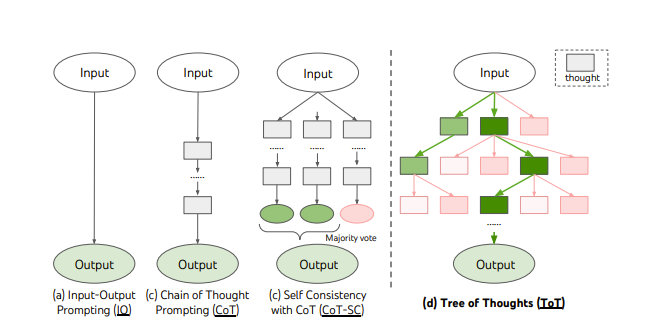
The idea of the Tree of Thoughts is to go through multiple reasoning routes via backtracking and expansion to find the best chain of thoughts that should lead to the conclusion by having each thought scored and put in a priority queue for future expansion! So we have a tree expansion thus this is a tree of thoughts!
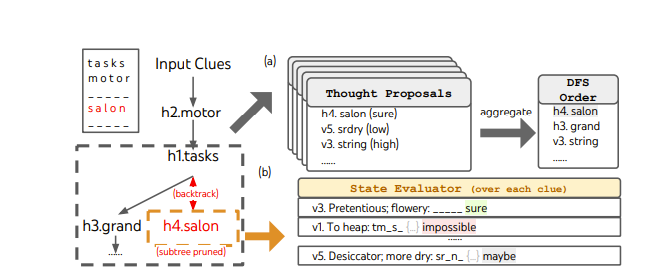
I think this is very much inspired by the calibration papers. This was pretty cool but was far from the end as now researchers are starting to use graphs for searching.
Beyond Chain-of-Thought, Effective Graph-of-Thought Reasoning in Language Models
The idea for “Beyond Chain-of-Thought, Effective Graph-of-Thought Reasoning in Language Models” was that in the chain of thought we are assuming a linear form of thinking. In that we first do x, then y, then z and we arrive at the answer. But in reality, our thoughts may be way more nonlinear with loops/more graphical.
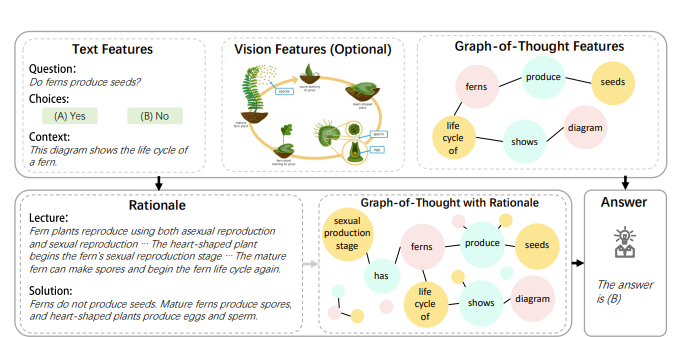
But how do we actually represent this? First, the authors make a “Thought Graph” which then gets encoded in a GNN
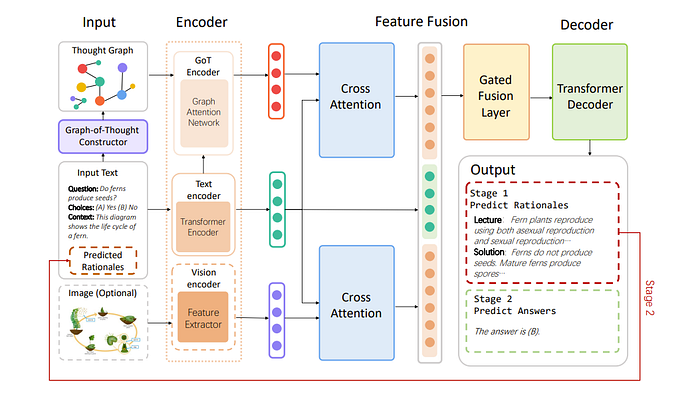
which then does cross attention with text and then fused to output the rationale! This does feel a bit like “GIT-Mol: A Multi-modal Large Language Model for Molecular Science with Graph, Image, and Text” where the authors aligned LLMs with Graphs but here the graph is constructed by a component called “Graph-of-Thought Constructor”. What does this module do?
Graph-of-Thought Constructor
The process for graph construction goes through ECC which stands for “Extract-Clustering Coreference” process. The input is the input text of question, choices, and context

The idea is given a bunch of thoughts on the text, and we generate knowledge triplets. In the paper, it does say something like for each thought we will have a knowledge triplet of x, y, z which is like
Earthquake(thought x) comes from(edge x y)−→ {earth, quake}(thought y) means(edge y z) −→ {ground, shake} (thought z).
but in the code, the triplets seem to refer to subject, relation, and object pairs so I think the idea is given the input text -> we generate knowledge graph triplets.
Then, for every node in the knowledge graph, we see if there is a co-reference which means to nodes are referring to the same object. Then we can connect both triplets at that node and if we continue we get a graph representing the input!
The initial representations before going into the GNN are taken from the text encoder using clever processing of putting each node in something like HTML tags

and then getting the representation from the tags after putting it through the text encoder!
Now, after all this it does seem to outperform chain of thoughts slightly
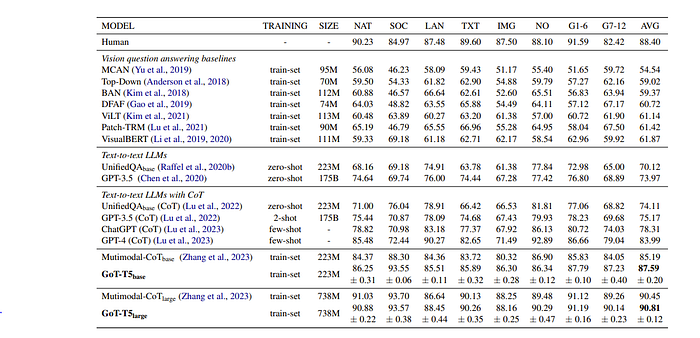
which I was honestly surprised by since I assumed having a graph-like knowledge structure is beneficial. One part I didn’t understand here is that the graph is only applied to the input prompt. I think this means that this method will have a greater understanding of the prompt but I don’t think it means that the thoughts will be graphical. I think the person behind this repo agrees with me as he writes “I believe this approach does not truly embody the essence of GOT, as each node does not represent a distinct thinking step but rather converts the natural language prompt into a graph format.”
Another paper that is more focused on increasing logical capability with graphs is “Boosting Logical Reasoning in Large Language Models through a New Framework: The Graph of Thought” which boosted performance over the tree of thoughts by around 20% on most logical tasks.
Boosting Logical Reasoning in Large Language Models through a New Framework: The Graph of Thought
This paper highlighted a flaw in the idea of three thoughts by highlighting Goldbach’s Conjecture

where for the solution of this conjecture, “mathematicians do not attempt to enumerate all possible techniques and theorems. Instead, they reason backward from the conclusion…. They identify promising avenues of research, and ascertain the essential foundational knowledge required to pursue a particular line of thought. Importantly, different lines of thought are not isolated; they are interconnected and collaboratively contribute towards forming the final solution”
which is in direct conflict with the Tree of Thoughts as it leads to an open-ended search for a solution with exponential expansion of tasks.
To resolve this conflict the graph creation starts from the final target, such as “Solve Function”. The authors do not provide the answer beforehand just the general task final state.
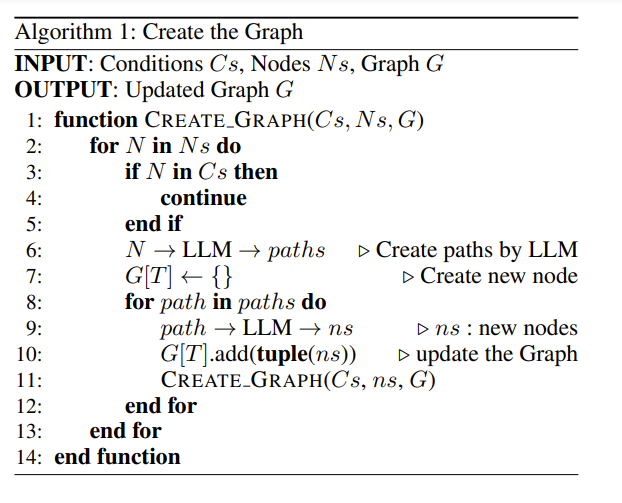
The authors define condition nodes as nodes “which can return to any node as long as there’s a path between them” I’m not too certain what they are overall the strategy seems to be
- Ask LLM to find paths to I assume the final node given the current node information
- Create new nodes that can reach the current node.
Next, the graph is updated by adding new condition nodes if they are deemed to be returnable nodes. My understanding is this is done by first checking if all the nodes in path are in the condition nodes and the current node is definitely in paths. To confirm that the current node is definitely in paths the authors did a pretty brute force method of asking the LLM n times whether it thinks the node should be in paths to be absolutely sure.


An example of this in say polynomial factorization is below!

where the final state is Solve Function! I think I’ll have to read the code to fully get it but I think the main idea is definitely cool although a bit task-dependent. Also as the repository owner mentioned, the ability to delete nodes might be valuable as well. Another critique is it’s relying purely on LLMs while I personally believe using external logical engines or even GNNs should benefit this somehow.
The final Graph of Thoughts paper we will check is “MindMap: Knowledge Graph Prompting Sparks Graph of Thoughts in Large Language Models”
MindMap: Knowledge Graph Prompting Sparks Graph of Thoughts in Large Language Models
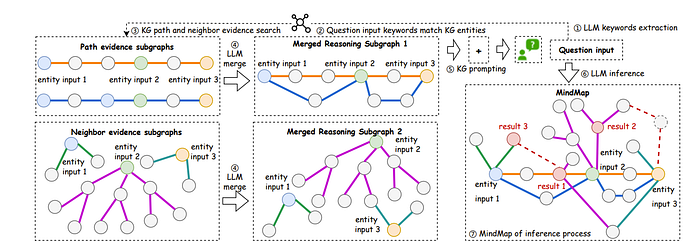
This method follows 3 steps
- Evidence graph mining where given the input text, we retrieve knowledge graph triplets from the database relating to the question
- Evidence Graph Aggregation is where the LLMs comprehend the given knowledge graphs to build a reasoning graph. My understanding is this simplifies the knowledge graph triplets to be one simplified unified graph in the form of natural language.
- LLM Reasoning with Mind Map
For this, the authors prompted LLM with a prompt of 5 components which has a system instruction, a question, evidence graphs Gm, a graph-of-thought instruction, and exemplars.
A good explanation of all these techniques are given by their figure below
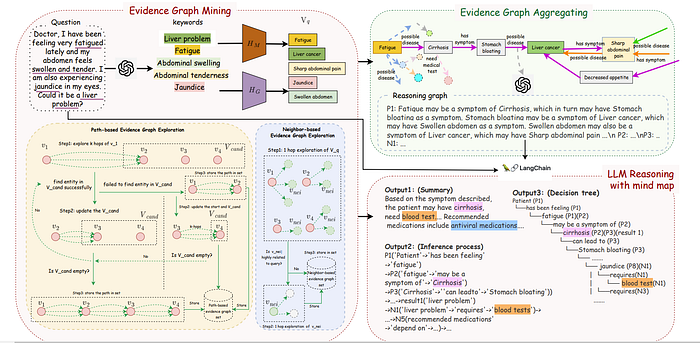
I think I’ll come back to this since I think I didn’t get the retrieval and final parts completely. My understanding is the retrieval part gets relevant facts from the KG database with a bit of RAG things. The second part encodes that into natural language. Finally, for the third part, I couldn’t find what exact kind of “langchain technique” the author used for the final stage.
Now, I think we did cover most of what there is to Graph of Thoughts but I think I am curious what are logical techniques fundamentally missing from LLMs. Or more of what can we expect LLMs to always be good at?
Analysis of LLM Reasoning
Towards Understanding Chain-of-Thought Prompting: An Empirical Study of What Matters
Counter-intuitively, “Towards Understanding Chain-of-Thought Prompting: An Empirical Study of What Matters” shows that when explaining in chain of thought, “the validity of reasoning matters only a small portion to the performance” only “being relevant to the query and correctly ordering the reasoning steps are the key” like so

of course, invalid reasoning does give some performance decline but it’s pretty good regardless!
Large Language Models Can Be Easily Distracted by Irrelevant Context
Another interesting paper was “Large Language Models Can Be Easily Distracted by Irrelevant Context” which analyzed how easy it is to distract LLMs with not even contradicting context but just irrelevant details by making a new benchmark called Grade-School Math with Irrelevant Context with examples like below

Overall, the authors found that breaking up the problem into subproblems, using self-consistency (majority voting with LLMs), and instructing to ignore irrelevant details can make the LLM more robust but without these, the performance drops significantly.
From these 2 papers, I’m getting the idea that LLMs expect the user to be somewhat like a teacher in teaching it what it should do in order for it to do the task. So essentially the details of what we say is not important as long as we are clear on what exactly it should do.
Now, when we do the chain of thought or any of these reasoning chain methods, are we getting what the LLM is actually thinking?
Language Models Don’t Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting
For “Language Models Don’t Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting” Anthropic along with Cohere and NYU. Anthropic seems to like interpretability papers.
For this paper, the authors found that the LLMs can start with an answer and then generate an in-plausible Chain of Thoughts to support the answer. To this end, the authors attempt to bias the LLM towards a particular choice in a multiple-choice question like below

To make the correct answer, the model must acknowledge the bias it has and correct it. However, this never occurs in production! Out of 426 explanations only once did the model mention the bias. Also, the biasing feature did cause the model to be more prone to output the choice that the authors were biasing for. The authors concluded that the explanations are “systematically unfaithful”
The authors then tested this across GPT 3.5 and Claude 1.0 to observe the following
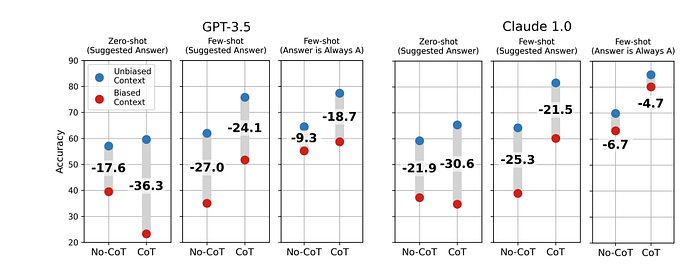
The biased context seems to greatly diminish the correctness of the output. Another part the Authors highlighted was for zero-shot, the output without COT outperformed the output with COT. This seems to suggest that COT can cause the model to move away from the correct output with its explanations. I personally think this is a symptom of RLHF as the authors suggest in that it’s just making the model follow instructions very well while not mentioning said instructions. I am curious how this work’s output may change when including the techniques from the irrelevant context paper. There are papers like “Question Decomposition Improves the Faithfulness of Model-Generated Reasoning” seems to indicate that if the LLM becomes more critical of the instructions these issues might be fixed slightly.
One strategy to fix the above issue might be self-correction where the LLMs where the LLM can evaluate itself to find a flaw in its logic and then fix it! Whether this was possible was evaluated in “Large Language Models Cannot Self-Correct Reasoning Yet”
Large Language Models Cannot Self-Correct Reasoning Yet
One question the authors had was “If an LLM possesses the ability to self-correct, why doesn’t it simply offer the correct answer in its initial attempt?” To measure this the authors tried having the LLM intrinsically self-correct itself but when doing so performance degraded. For why the performance degraded, the authors found that “The fundamental issue is that LLMs cannot properly judge the correctness of their reasoning” where on a certain benchmark called CommonSenseQA asking it to self-correct has a high chance of altering the answer which then biases the answer towards a slightly similar different answer.
I think this is a very human-like response to critique personally. So overall, I think currently there isn’t much value to self-correction. I do think the method of Tree of Thoughts and Calibration on scoring the output and choosing which is the best reasoning path does work but correcting the output seems misguided. As the paper puts it “If the model is well-aligned and paired with a thoughtfully designed initial prompt, the initial response should already be optimal relative to the prompt and the specific decoding algorithm.”
Another interesting paper is “The Impact of Reasoning Step Length on Large Language Models” It seems to say that just increasing the number of steps in COT helps with reasoning even with incorrect rationales.
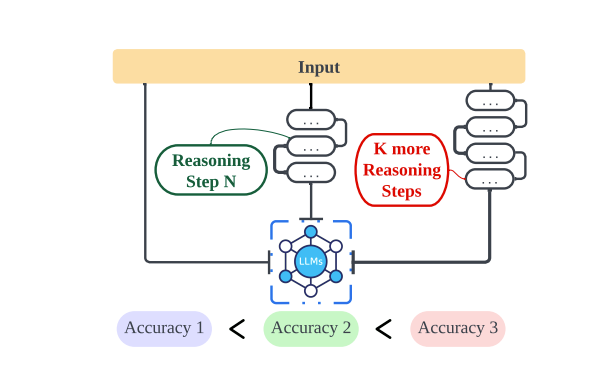
This is mainly done by increasing the reasoning steps in the demonstrations using GPT-4. Overall, for the chain of thoughts, it seems as though correctly teaching the LLM what to do is the most important and it’s not necessarily robust to anything outside the teachings.
Then, one idea is whether we can rely on an outside tool for this. One such method is “LOGIC-LM: Empowering Large Language Models with Symbolic Solvers for Faithful Logical Reasoning”
LOGIC-LM: Empowering Large Language Models with Symbolic Solvers for Faithful Logical Reasoning
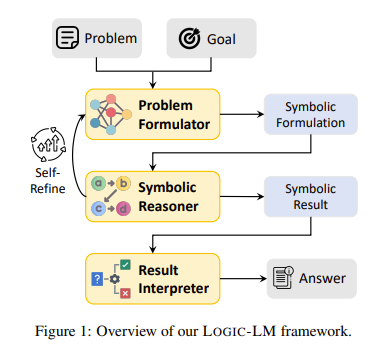
The idea for this paper is very simple. Since LLMs are not great at logic, let’s translate our problems to logic and solve them using a logical solver! This change was enough to boost performance by 18.4% across some logical benchmarks even using Chain of Thoughts. This does alleviate the faithfulness issue. A more comprehensive diagram is below
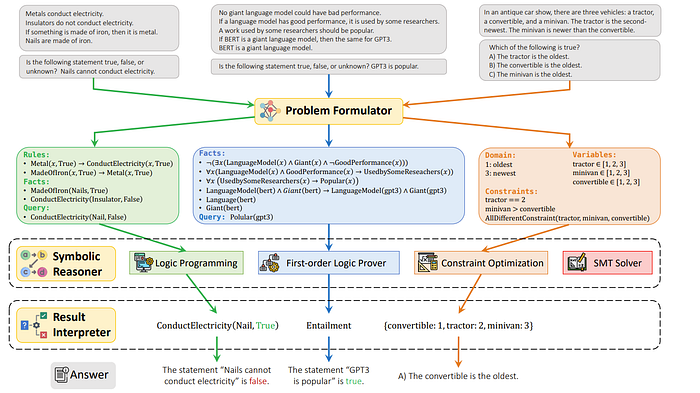
The list of solvers used is below
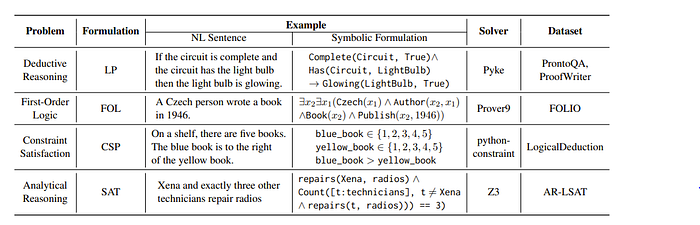
One interesting part of the evaluation is chain of thoughts was in fact detrimental or had not much use with this technique. So solely relying on external tools seems to be the solution
I think this is a more promising approach for LLMs+Logic in that it does not rely solely on the LLM to solve logical problems. While this is interesting, does this solve all the issues of reasoning/logic and LLMs? The authors highlight 2 issues
- We have to translate to a logical formulation so this does not work with natural language/defeasible problems like law.
- Mapping of some natural language to symbolic representations is non-trivial.
One slight critique I have is I do think it’ll be interesting to have this technique do an intermediate computation while doing say a chain of thought or tree of thought. In that I am very curious if this can say solve detective stories and find the villain based on intermediate calls to logical solvers. I think there may be a step missing here.
One potential idea is extending “Efficient Tool Use with Chain-of-Abstraction Reasoning” by Meta where LLMs are trained to decode with abstract placeholders which then can be used for the Mystery story.
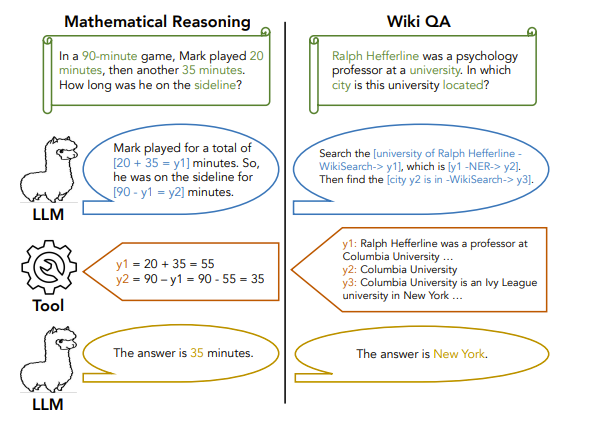
I think one assumption I’m making here is that the text can be separated from the logic being done which is a pretty interesting idea that may be False. I think there should be something internal to the LLM that calls for tools for logical processing which then supplements the answer. React agents/COT is the best thing we have now but it feels like the LLM is doing something in human terms of speaking before thinking.
Another more fundamental issue is these prompts are task and model dependent both for tool calling and chain of thoughts.
Then is the way to go instead to increase model capability? Now, there was actually one form of machine learning that did demonstrate impressive logical capabilities even beyond human made algorithms. That was AlphaZero!
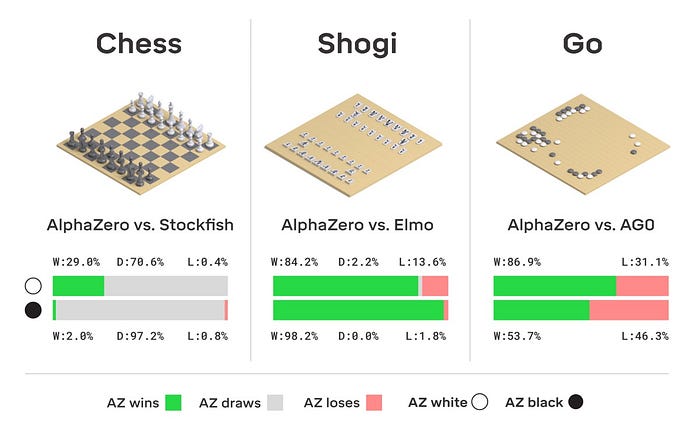
There seems to be something about self-play against itself and reinforcement learning that can lead machine learning algorithms to outperform the best of our logical engines! Then the idea is pretty simple. Can we do this self play with LLMs? One such paper is “Self-playing Adversarial Language Game Enhances LLM Reasoning” by Tencent AI Lab.
Self-playing Adversarial Language Game Enhances LLM Reasoning
Now, what should the strategy game be to do self-play with LLMs? The authors decided on Adversarial Taboo

The attacker wins if the defender says the word and the defender wins if the defender correctly guesses the word.
The state for this reinforcement learning problem is what the defender and attacker say. The action space is the token word space.
The reward is zero sum and is 1 if the attacker wins -1 if the attacker loses and 0 for ties. The game is zeros um and there is decay which is pretty standard for reinforcement learning.
Some pretty cool results is that this lead to the LLMs actually improving in their benchmarks.
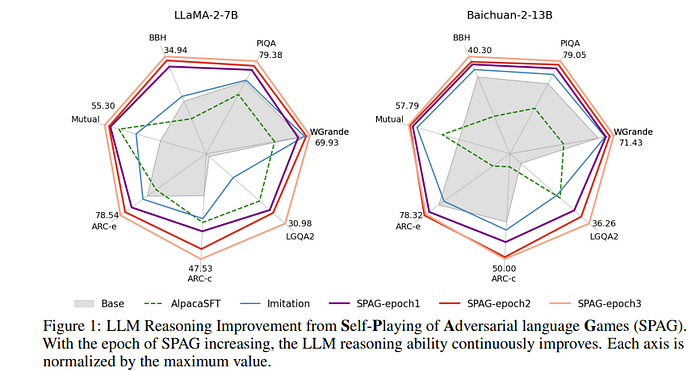

The reason the authors only did 3 epochs is because of compute also mentioned in their limitations section.
I do think this paper is one of the coolest papers explored in this blog. My main questions are
- Are there benefits of moving to a more involved game such as what Meta did with CICERO. I know Laion/a lot of open folks are trying to do this with chess. I remember the general conclusion was it became good at chess but not in terms of general abilities
- Can this technique be used with tools? In that can we have LLMs using tools doing self play?
- And of course I’m curious if this scales.
Another trivial issue that LLMs have that I wanted to highlight is counting! This has effect on reasoning as “Transformers Can Do Arithmetic with the Right Embeddings” highlights which argue LLMs do not have the ability to “keep track of the exact position of each digit inside of a large span of digits” which they proved by being able to do 100 digit addition with minimal training. Also, this allows for gains in other multi-step reasoning tasks too!
Transformers Can Do Arithmetic with the Right Embeddings
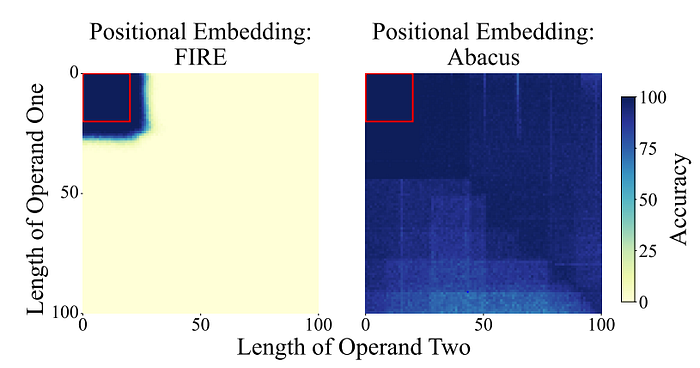
The authors propose the Abacus embedding to resolve this issue of inability to recognize digits. My understanding of this is pretty specific to addition but it’s an embedding specific to addition like so

Essentially positional embedding is added for each number and the LLM is trained from scratch so the authors were able to test the benefits of recurrence in this. In that having more layers in the transformer, even with 10x fewer parameters gives better results. One interesting point here is that we seem to assume that each number is its own token which may not be true in general.
I think the authors demonstrated this improved performance on both multiplication and array sorting as well
Now one obvious limitation of this paper is that it’s acting only on digits and not natural language. Can we extend this to a general language domain? “Contextual Position Encoding: Learning to Count What’s Important” by Meta accomplishes pretty much exactly this.
Contextual Position Encoding: Learning to Count What’s Important
In normal attention networks, the model has no idea which word comes before which other word which is solved by positional embeddings. Now what this paper’s authors noticed is that this makes LLMs understand token orders but not say what’s the 2nd sentence in a paragraph or what’s the 5th word in the 2nd paragraph etc.
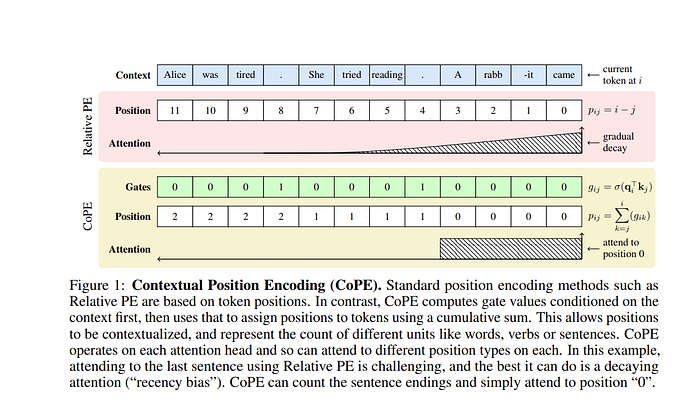
To do this we want to get a new positional embedding with which tokens we ignore. This is done by gating. The authors compute between the current query i and key j a gating value between 0 and 1.
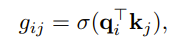
0 means that the key will be counted for the query token in the positional enbedding and 0 means it will be ignored. The authors stated to count the sentence separation between tokens i and j, this gating will only be 1 for periods. Then the count can be recovered by
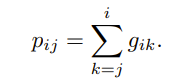
Then we just train! The above value can be a floating point so then is interpolated between embeddings. One part that I especially found interesting is it connects positional embeddings to which part of the attention it highlights! In that it forces the LLM to pay attention to say the same sentence etc. This is motivated by section 3.1 of the paper which I didn’t fully get but when I do I will put here. This is motivated by section 3.1 of the paper. The idea is as follows
Let us look at yyxyyxyy(we assume both y and x are one token) with the task of finding the last x. Then, we want to attend to that x. So we expect a larger attention value than all other tokens like this
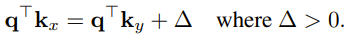
Here, if I understand correctly, this is the attention on the first x. Now, because of softmax for the attention value to be something like
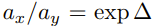
Now, for the x tokens, let us assume both of them have the same keys. Then, the only difference between these 2 xs will be the positional embedding so we have
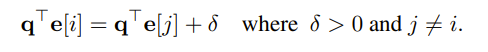
and for the attention,
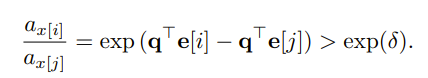
Here, if we want the last x on position i then we expect for the last token to have a high attention than just some δ. So the authors decided to just multiply it by i which I don’t fully get but I think may be right. So they end up with the formula
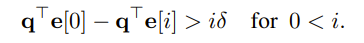
the position 0 is treated as the last position of y.
Now, if we multiply the above two attention fractions we get
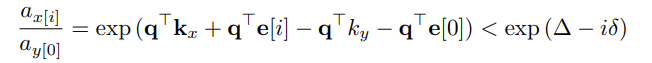
here we see y will have a higher attention than x if
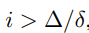
I think I’ll revisit here once I get it.
But one cool effect is with this positional embedding scheme
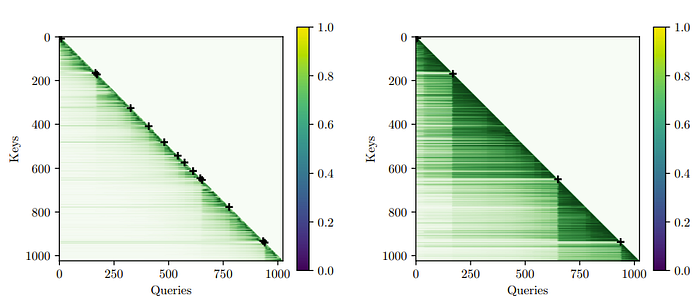
it can attend to abstract elements like current paragraphs and sections! One downside of this approach in my opinion is that it requires training from scratch but I think a separate model has to be trained on what you are counting.
Now, that was on positional embeddings but another idea may be that for current LLMs, the training objective is to predict the next token. One guess is that this makes LLMs pretty good at writing stylish texts but without much long-term planning which is bad for reasoning. So another cool paper by Meta is about what happens if we predict multiple tokens at the same time with “Better & Faster Large Language Models via Multi-token Prediction”
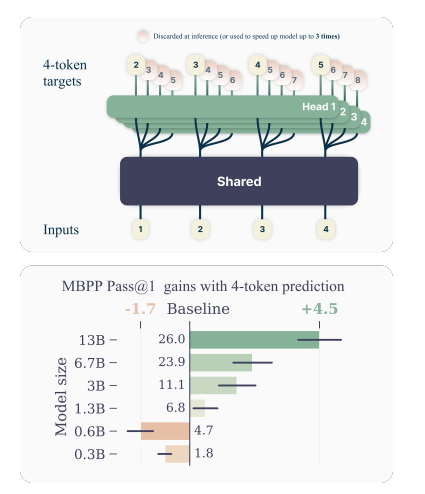
Better & Faster Large Language Models via Multi-token Prediction
To accomplish this, we modify the cross-entropy loss from
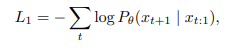
to
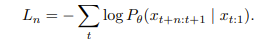
then given the same shared trunk of the processed inputs. My understanding is then we have n number of heads responsible for each ith token in the future which is all processed in parallel! I found this pretty counterintuitive because it’s predicting without the knowledge of the previous token except for the first head but I do get that it can be more robust!
Now, to the results. It does improve results on coding benchmarks but according to this reddit post is worse in natural language so a bit of mixed results but seems to indicate better reasoning. It may be too early to tell. I’ll add more insights into the results if I get time.
Conclusion
Overall this was a bit disorganized but I think I got a good sense of what are the current reasoning capabilities/research in reasoning with LLMs.
Overall, my conclusion is I think there is a distinct lack of use of GNNs and possibly reinforcement learning for LLMs to improve reasoning.
I think GNN+tool use may be interesting.
The paper that I personally found to be most practical is “Boosting Logical Reasoning in Large Language Models through a New Framework: The Graph of Thought” as it can just be a prompting strategy.
There is definitely a lack of research in defeasible logic but overall I think there is a distinct lack of performance on normal logic with LLMs so I think it makes sense.
I think the future direction of this field will be lora+self play+GNN+tool call all in one paper. But we will see! And do let me know if there’s any mistakes/points I missed.
