Understanding Graph Machine Learning in the Era of Large Language Models (LLMs)

Hi! These are my notes for a presentation I’m planning for the Huggingface Reading Group on Saturday. If you want to see a recording, check out here!
The goal of this blog is to understand the current state and limitations of making Graphs and LLMs work together. I will begin by following Graph Machine Learning in the Era of Large Language Models (LLMs). The goal of this paper is to
- Detail the history of Graph Machine Learning(Graph ML) to the current state of using Graph ML along with LLMs
- Find the major categories of how Graph ML is used with LLMs along with their advantages and limitations along with possible solutions.
Now, how do we even start with working with graphs? We do want to get some vector representation of the graph of some kind in order to do machine learning. However, how do we work with the potential exponential number of nodes and edges?
Random Walks
This is a basic idea that was built up to “node2vec: Scalable Feature Learning for Networks” by Stanford University in 2016. But the premise is
- We want to do classification over nodes and edges in a graph, a bit like in a recommendation system where given the graph of what movies you like, whether you will like this new movie etc.
- For this, we need to get the features of each node in the form of vectors which we can then classify in an Unsupervised way, as we are assuming a lack of labels.
- These features can be made using the concept of random walks.
- We are working on an undirected unweighted graph
The idea of random walks is very simple. You basically start at a node in a graph and then just do a random walk over the graph by going through random edges to visit other nodes.
Now how can this help in finding embeddings?
We first assume that nodes that are closer together are similar/in the same neighborhood. For example,

Above, u and s1 to s4 are similar/in the same neighborhood while u and s6 should be dissimilar/distinct communities.
Now, the next idea that Random Walk papers came up with is let’s make a lot of these random walks and record the nodes visited. So we have
u, s1, s2
u, s4, s5
s3, s4, u
etc. All random walks. Now if you look at the above, it does resemble tokens or words in the English language. And from words, there is already a known technique called word2vec to get vector embeddings of each word called skip-gram!
Skip-gram
I mainly learned the idea from here which I highly recommend people check out but the idea is

- We pick a random target word/node from within the random walk sentence with a window of let’s say 5 nodes. So there are 2 nodes before the chosen node and 2 nodes after the chosen node.
- Using that word embedding, we have one hidden layer and then a softmax to see what those 4 unmentioned nodes are.
- We optimize the embeddings so that it can predict reliably what nodes it is connected to
So essentially, the idea behind Random Walk is just to convert the graph problem to NLP and solve from there.
However, I think you may notice that this is very simple. Just having one neural network do a prediction in one iteration sounds too simple.
And in fact this was true. There is a new kind of technique that works on graphs called Graph Neural Networks(GNNs)
GNNs
The paper highlights 2 types of GNNs. The first type is called the “Neighborhood Aggregation-based Model” which I have worked on a bit before. In particular from a paper called House-GAN, so I will explain the concepts of basic GNN through that lens because I found the visualizations in the paper really helpful when I was learning these types of GNNs.
HouseGAN tries to tackle the issue of layout designs of rooms. In particular, given that we have certain types of rooms we want, and also some graph information on what room is connected to which other room, we want to generate an image of the layout! A bit like below:
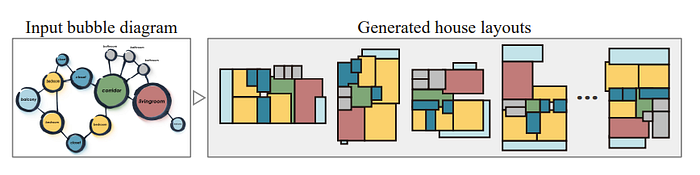
Now, how will we do this? If we were to do this directly and generate an image in one go, it would be very hard to have the constrained information of the number of rooms and the room connections present as well. To tackle this task, this paper decided why don’t we make each node of the input graph become an image of a room like so

So we can combine all the rooms in all the nodes into one image to get our final image! However, there is an obvious question of how the node knows where to place the room in order to not overlap or be in a totally wrong place compared to what we want. Or to be more specific, we do train our model against real data so that it tries to generate in the right place but how does it know the surrounding information that it needs to know to generate the room image?
This is where the important concept of message passing comes in for GNNs.
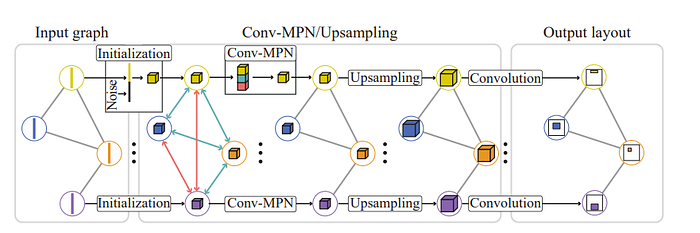
The main idea of message passing in GNNs is we try to make a given node understand what is currently going on everywhere around it. For this, in this paper, we start with randomly initializing each node with a vector. This is not a typical GNN thing to do but this paper is about GANs so that was the reason for random initialization. Let’s call this representation g and let our current room be r
Then, we get our current vector representation g which we want to update.
For the neighboring representations, we get
- The sum of the representations of the nodes directly connected to r(If you are a computer science buff you might notice this is the same as multiplying all the representations by an adjacency matrix)
- The sum of all the representations of nodes not connected to r
Finally, we pass through a neural network(in this case CNN) to update r.
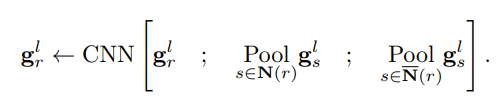
If we do this for every single node across multiple iterations, we can make each node aware of its surroundings and able to generate rooms in the right place!
As this survey paper puts it, there are 2 phases, aggregation of the neighbors and the update
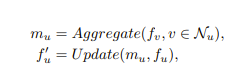
One interesting improvement here came from an observation that we are giving a bit of inductive bias on which information to focus on and which information to ignore. For example, we ignore nodes that are 2 neighbors away in the above! So in “Graph Attention Networks” this was kind of addressed by having our model be the judge of how much attention to pay to which node.
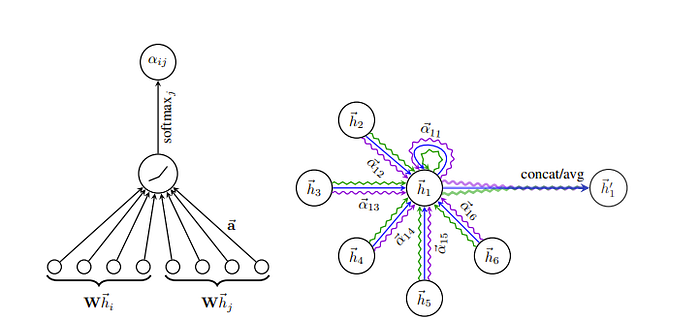
However, the limitation here is pretty apparent too. If the graph is very large, while this method can gain information about the local neighborhood of each node, this network does not have the capability of representing very large graphs at least not without a lot of iterations. To this, the paper presents the “Graph Transformer-based Model”
Below I am assuming you know the basics of transformers but I might edit here to add a preliminary intro.
Graph Transformer-based Model
One of the leading papers for Graph Transformer models was “Do Transformers Really Perform Bad for Graph Representation?” by Microsoft.
At the point of time when the paper was published, around 2021, it was around when NLP and CV tasks were getting boosts in progress while for graph tasks nobody has successfully found a way to use transformers properly. In the graph leaderboards, the typical neighborhood based GNNs were dominating while attention was perhaps used a bit in aggregation but not much in anything else.
To combat this, the authors improved graph encoding by incorporating “structural information of graphs into the model” by using encodings!
The basic idea seems to be the following:
For the typical self-attention on the Node features, which in this case doesn’t use neighborhood based features, there is no inductive bias on the data. So self-attention has a very hard job updating the node features. I find this interesting because I remember seeing the exact same thing happen in computer vision until the Swin transformer came along to give that inductive bias.
The first inductive bias the authors thought of is highlighting node importance using a technique called centrality encoding. In particular, nodes with high degrees should be more valuable than nodes that don’t have many connections. So, they add to each node feature information on the number of nodes coming into that node and the number of nodes coming out like so
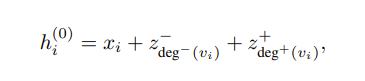
Where each z is an embedding that is learned which maps a number to a vector.
Next, one thing that if you know transformers you might be curious about is what we do about positional embeddings. For example, usually in text, we add positional embedding to the input of the model to say this word is word number 1 this word is word number 2 etc since transformers have an issue telling apart which word is which otherwise! Even for images we can make the top left corner be token number and and go row by row.
However, the interesting thing about graphs is we can’t necessarily do that. In that we can never say which node is number 1 since we don’t know where the graph starts from necessarily. In fact, any order of positional embeddings on nodes of a graph can technically be correct.
So, the authors thought of doing spatial encoding. The idea is very simply, why don’t we just use the shortest path between 2 nodes to denote the “distance” between each node? Then we can just embed that distance in an embedding vector like the above and add it to the attention matrix! The reason we do it at that stage is because the attention matrix has size nodes times nodes. So it matches in size.
Finally, the authors added an edge encoding which I think is mainly there for the task of molecular prediction they focused on. From what I understand, they wanted the edge information to be some kind of correlation metric to I think tell how important the connection is. So how it’s computed is
- We have the shortest path from node i to node j
- We take the edges along the shortest path and their learned embeddings
- We do a dot product of each of those edges with each node’s original features.
- We add that constant to the attention matrix index i j so we are left with
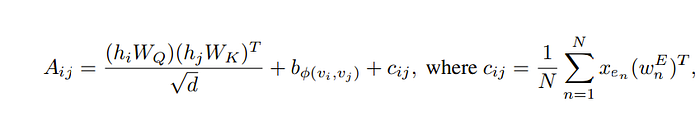
In total, it looks like below!
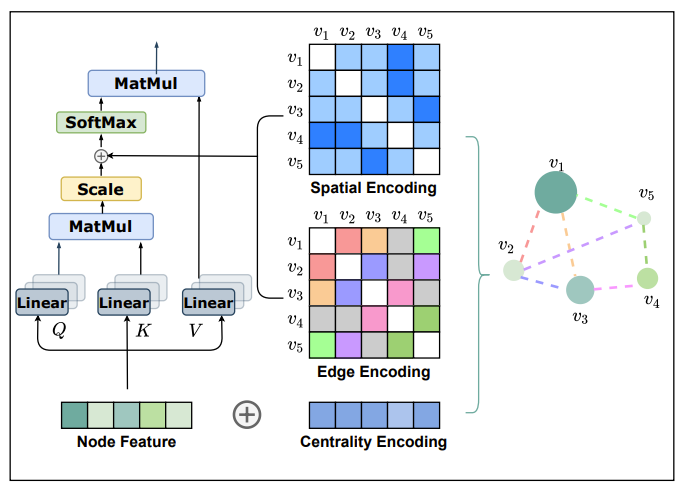
So essentially the theme of these types of GNNs seems to be adding some structural information to the self-attention, we can give some weak inductive bias to make Graph Transformers perform well.
However, much like with any attention-based models, this method, while it performs well, has its own issue where we need to do the O(N²) computation for the attention matrix. This may be fixed by models such as “Graph-Mamba: Towards Long-Range Graph Sequence Modeling with Selective State Spaces” which applies a model called Mamba which can approximate attention but with way less memory consumption for big sequences. But I think it’s too early to say yet.
Now we have a way to get more decent representations, can we make them even better? The main way seems to be through self-supervised learning!
Self-Supervised Graph Learning
Graph Contrastive Learning
The idea show by “Graph contrastive learning with augmentation” is pretty simple. Like for any contrastive learning project we slightly perturb the data and try to make the representation as close to the original data as possible!
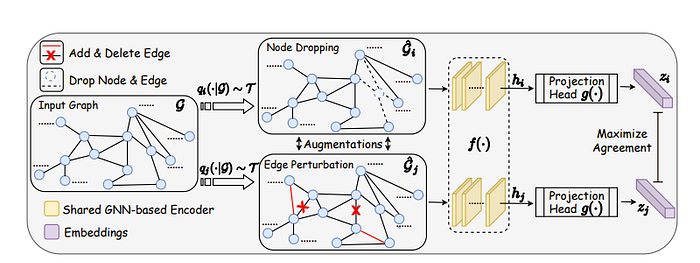
The main interesting parts if we do this in graphs is we can have node-level contrastive learning as well as contrastive learning over the entire graph. However, one obvious issue here is once we train such a constrastive learning model we cannot increase the size of the graph we input to say 2 or 3 times, at least not currently.
Another part that I want to highlight is the above works only under the assumption that small changes in the graph/feature space don’t change the graph too much.
Graph Generation
Inspired by Masked Image Modeling, the paper “GraphMAE: Self-Supervised Masked Graph Autoencoders” tackles hiding the features of some nodes and then trying to reconstruct them using GNNs so that in the end, the node features are similar to the input ones!
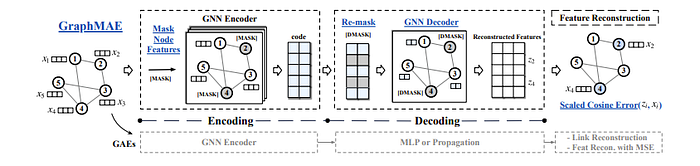
Now then how can LLMs play a role in Graph learnings?
The first way is making the graph and the features of the graph better before working with the GNN
LLM to help with GNN tasks
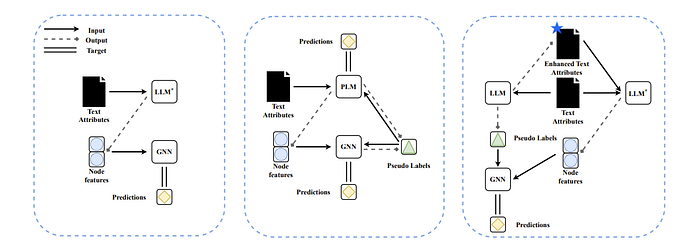
For example, for “Exploring the Potential of Large Language Models (LLMs) in Learning on Graphs” the idea seems pretty simply to use LLM with visible embeddings to encode text or to have, for example, ChatGPT to make better text than encode them which the GNN then works on
One of the more interesting method here I found was “Empower Text-Attributed Graphs Learning with Large Language Models (LLMs)” which used LLMs to predict edges missing before plugging into a GNN!

Also, if we want our GNN to work across multiple tasks there seems to be a way to do this. For example “One for All: Towards Training One Graph Model for All Classification Tasks” presented a way to unify tasks and combine feature graphs with a prompt graph to guide the GNN
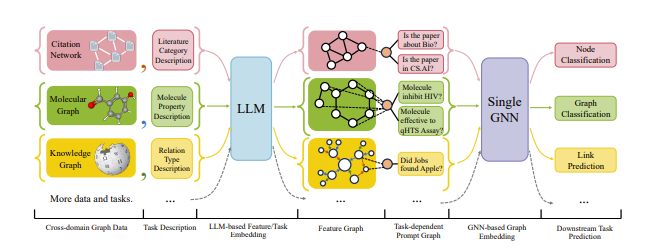
Now, not so much the self-supervised approaches, but this one has its own limitation too of needing labeled data to train the GNN on. So can we cut out the GNN altogether and have the LLM solve graph tasks by itself? Or to be more specific, how can we plug in graphs into LLMs so that LLMs can solve graph problems?
Solving Graph Problems with LLMs
There seems to be a lot of work of just figuring out what text is best to represent a graph.
Some interesting ones include “Can Language Models Solve Graph Problems in Natural Language?” where the authors ask the LLM to build a graph from text descriptions
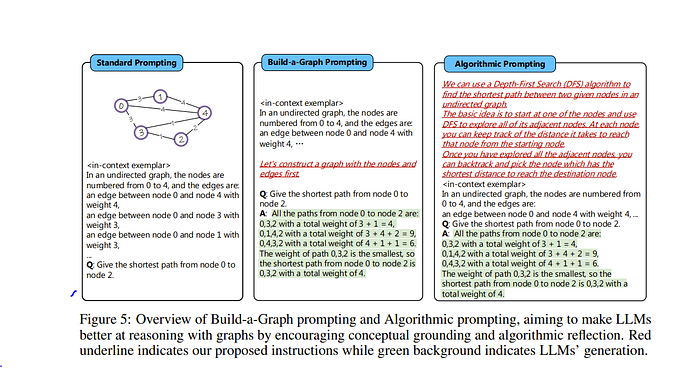
which improves the LLM’s understanding of the graph like above. Another strategy I learned from the paper is that there is something called Graph Markup Languages which “GPT4Graph: Can Large Language Models Understand Graph Structured Data? An Empirical Evaluation and Benchmarking” used along with self-prompting to improve graph understanding of the input before the final output.
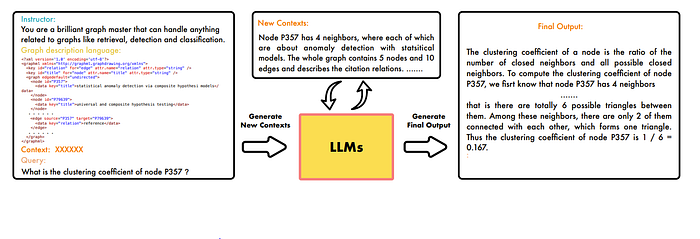
So overall, for this method of inputting graphs into LLMs, the major strategy seems to input data, make LLM understand the graph, and then ask the question. However, the limitations are also pretty clear. This method is not scalable to large graphs due to context length reasons. Also, the paper highlights that for new tasks, new prompts may be needed which take ingenuity and effort to make.
Then, what we want is we want an expert pre-trained GNN to somehow customize the output of LLMs.
Combining GNNs with LLMs
For this, we can get inspiration from BLIP 2 on how exactly to combine text and image features!
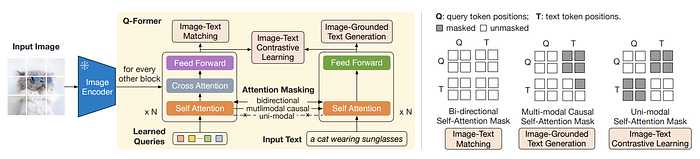
The idea is pretty simple.
- We have a transformer network for images and another transformer network for text
- Instead of inputting the image tokens into to the image transformer network directly, we input learned query tokens and add in the image information by cross attention. The reason we do this, according to the paper, is to act as an information bottleneck that gets information from the image encoder features and in a way, compresses them a bit like a vae.
- With this rather simple technique, we can combine images and text, with some clever attention masking, to generate text about the image, and make good image and text representations like CLIP.
So now, the question is can’t we just apply this technique to graphs using the features we learned with GNNs? And the answer is yes. In “GIT-Mol: A Multi-modal Large Language Model for Molecular Science with Graph, Image, and Text” exactly this idea was presented for a Graph, Image, and Text modality fusion using Q-former! Which, as can be seen below, do classifications and even captioning based on even just an image as a modality. It’s pretty much the ultimate transformer in a way.

Another interesting method was one in which we tokenized graph to use in the LLM. For example, in “Gimlet: A unified graph-text model for instruction-based molecule zero-shot learning”, the graphs are tokenized with positional embeddings based on the shortest distance that we mentioned before! However, one slight difference to regular nlp is that it’s added to the attention matrix and not the hidden node states(which is the same with the above PE for graph transformers) like so
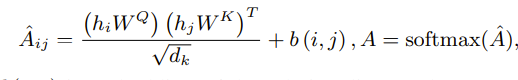
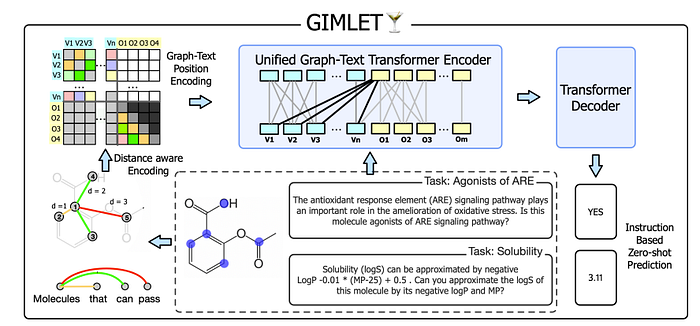
Also, one important part here is the graph “tokens” are not actually tokenized to my understanding. We just have the graph embeddings and just add the positional embeddings to them.
However, there is a limitation to this idea. And that is that it’s bottlenecked by how good GNNs are. The paper mentions that GNNs suffer if
- Adjacent nodes lack similarity, which is one of the assumptions
- They can’t generalize to out-of-distribution data
Overall, there seems to be some work that uses LLMs to fix this which I think is a bit less exciting idea compared to a unified model like the above.
Now, finally, how can we use graphs to remove hallucinations? Here is where knowledge graphs come in.
Knowledge Graphs
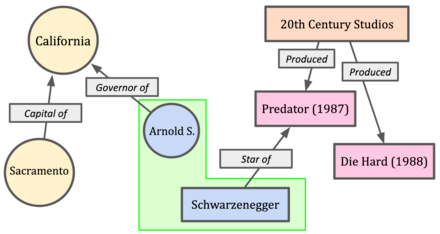
Knowledge graphs(KGs), as is shown in the image above, is made of triples of facts. So for example, (Arnold, governor of, California) is a fact. So the idea is can we use LLMs with these series of facts to make the outputs more factual?
Enhance Training Data with KG for LM training
The first way we can use KGs is by modifying training data. One particularly interesting work, “K-BERT: Enabling Language Representation with Knowledge Graph”, took the input sentence, and enhanced it by adding details from knowledge graphs like so
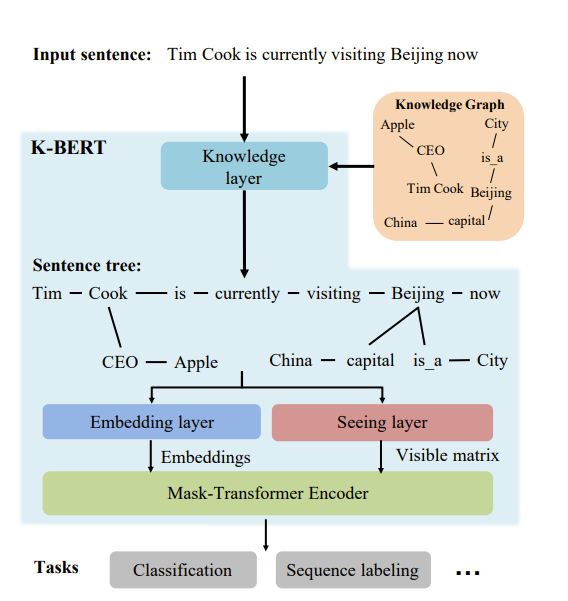
Interestingly, this uses attention masking so that the KG is only visible from he specific token it affects like so!
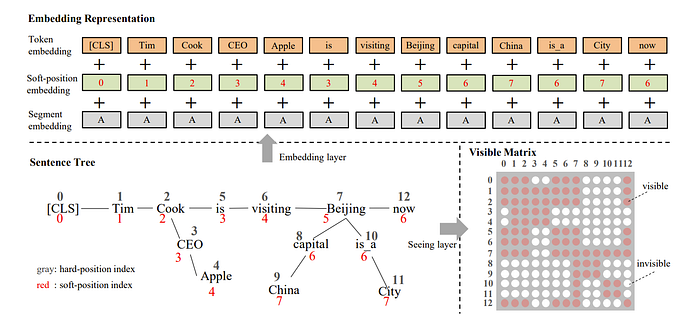
Another more interesting direction is to encode the knowledge graph directly into the architecture like “ERNIE: Enhanced Language Representation with Informative Entities” which first proposed the idea of encoding the entities directly into our tokens. For example, in the above, encoding Tim Cook whenever Apple is mentioned like so
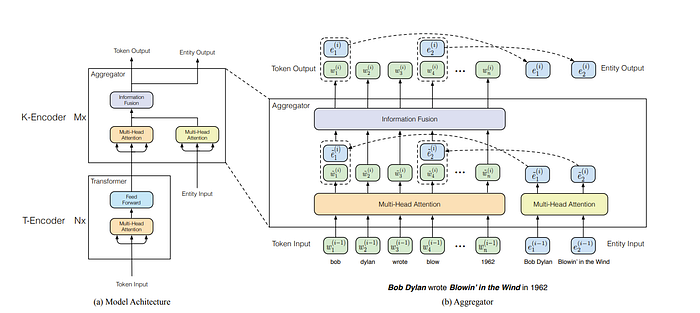
So here the token for bob gets the tokens Bob Dylon encoded into it and blow gets Blowin’ in the Wind encoded into it from the tuple pairs of KGs! Notice here that the token input and the entity input do not have to have the same size. In fact, let’s say we take bob, 1 token, and concatenate it with say 2 entity tokens for Bob Dylan. Then we can do the feed-forward network structure below and then separate them after the Information fusion stage. There is no size issue present here!
For the information fusion it is given by the formula below where wj is the input tokens and eks are the associated entities.

There has been an improvement on this, for example, KLMO which also encoded the relation part of the KGs by Tencent but I think Ernie does give enough of the idea on this approach.
However, there is also a bit of an issue with the above approach will be expensive to train as we are significantly modifying the LLM. Can we somehow just do something like a LORA instead? And the answer is yes we can. In “KALA: Knowledge-Augmented Language Model Adaptation”,
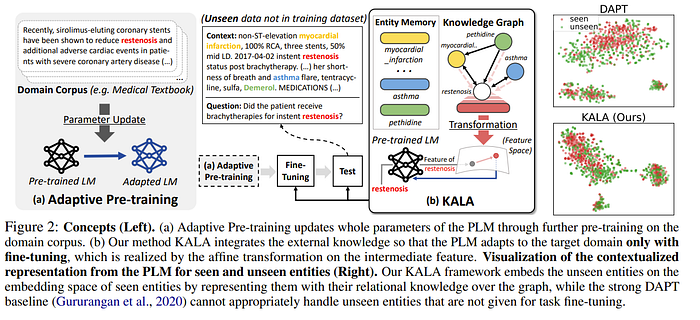
In this paper, the goal is to predict a label y given input x so we have
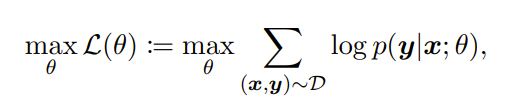
So the goal with the KG becomes to do the above with the knowledge graph embeddings. To this end, the authors use a network to find the scales and biases to apply to intermediate layers given the entities found in the prompt like so!(I will try adding the specifics of what KFM does/embedding when I get a chance)
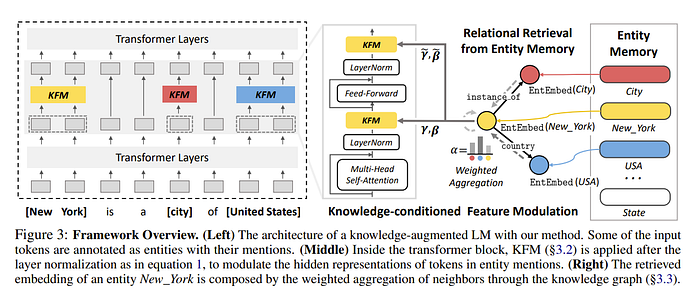
There is also ways to modify pertaining tasks where we try to make the model guess the missing entity using KGs by randomly replacing some entities with other entities. But I’ll skip forward to the next section for now.
Do inference with KGs! This may be what people who don’t have many resources will be interested in. How can we just use KGs for improving say a GPT 4 output on a prompt?
KGs for inference
The first approach the paper highlights is just using KGs on the prompt to see if there’s any context we can add and then do something like RAG on it like so
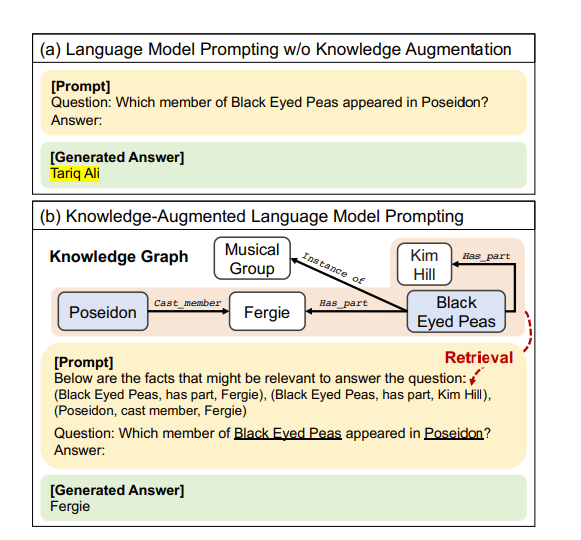
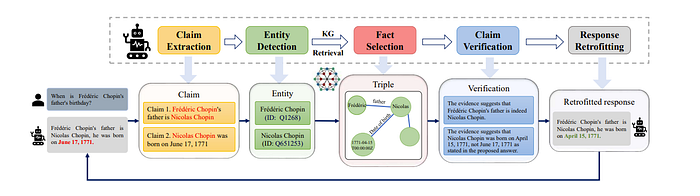
However, this does rely on the LLM a lot to understand the structure of graphs inherently. There seems to be a lot of papers on this task which all seem to point in the direction of making the reasoning process of the LLM more clear and grounded in KGs. Additionally, papers like “Mitigating Large Language Model Hallucinations via Autonomous Knowledge Graph-based Retrofitting” prevent hallucination of LLMs by first having the LLM output a draft answer and then extracting claims, verifying until the answer seems correct
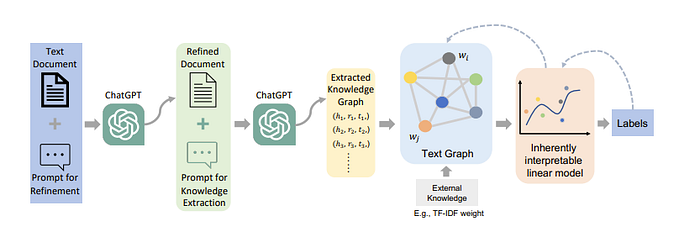
Finally, “ChatGraph: Interpretable Text Classification by Converting ChatGPT Knowledge to Graphs” first uses ChatGPT to make an unstructured document/prompt into knowledge graph pairs and then uses a trained GNN to predict a label from the graph constructed by those KGs which I thought was pretty interesting. Basically, if you can’t train the LLM offload the work.
Finally, let’s explore what is missing from the current field
- Generalizability
GNNs suffer from OOD samples. LLMs seem to help in this but it’s yet to be seen if GNNs are the best architecture for generalizing or whether there will be some new graph foundational models. For this the paper suggests doing more multimodal research in text/graph/image datasets
2. Efficiency
Graphs in particular can grow in size exponentially with each added node which makes working with LLMs, for example GPT4, very expensive. There is a need to be more efficient.
Finally, for me personally, I did find this survey interesting but I was a bit surprised that there doesn’t seem to be much on
- Constrained generation + graphs or graphs for planning for LLMs
- Increasing math capability/logic using graphs
- Quantizing graphs
But I might have missed them. Anyway hope you all enjoyed.
