Literature Review on Task Planning with LLM Agents
Here, I plan to find the current state of the art on the best ways to plan tasks/to-do lists for LLM Agents! The main motivation for this is I was doing research on pen-testing with LLMs and I noticed figuring out the best way to add/remove tasks is a very important part of this. And to me, it was a bit unclear what’s the best way to do this. Is it to have the to-do list in the form of a JSON and to keep forcing the LLM to output a JSON? Or is it to use React to add/remove/modify tasks or do we have to have the entire task creation process in context?
To get a basic understanding, I plan to look at papers from here!
Disclaimer
I wasn’t able to find the answer to the above as of now but I think there are a bunch of interesting papers out there.
The first fundamental paper for LLM agents that I know of is “ReAct: Synergizing Reasoning and Acting in Language Models”
ReAct: Synergizing Reasoning and Acting in Language Models
The paper itself can just be described by this diagram:

The essential idea of this is that given a task and tools we want to use, we can have the LLM iteratively
- Think
- Use the tool with arguments/write code etc
- Get observation on what is happening
The prompt for this is given in Langsmith here and it’s just
Answer the following questions as best you can. You have access to the following tools:
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought:{agent_scratchpad}For the results, much like with other methods combining self-consistency and chain of thought makes it pretty good

Now that was the main paper that I think boosted the popularity of agents. Now, has there been improvement since then? One obvious issue as is with most LLM things is hallucination. We can definitely use ReAct but if it goes down the wrong reasoning chain we are just wasting tokens.
One solution proposed was “Reflexion: Language Agents with Verbal Reinforcement Learning”
Reflexion: Language Agents with Verbal Reinforcement Learning

The idea for this work is pretty similar to ReAct but
- we add an evaluation step that has the LLM or external function tell us if the output/current trajectory is correct
- Then, there is a reflection stage which corrects the reasoning and
- Finally, the action is corrected
Now while this seems great, the issue is that this paper doesn’t necessarily work. Google’s Deepmind made a paper “Large Language Models Cannot Self-Correct Reasoning Yet” which mentioned a lot of self-correction papers including Reflexion in that they don’t work by having the LLM self-correct themselves. In fact here it worked since the authors used ground truth labels to help correction. The part that I think the authors agreed on is that if you use external signals then it works.
But what if you don’t have an external signal on what is good or bad? Can we still somehow make a better plan than ReAct?
One common strategy in ”LLM+P: Empowering Large Language Models with Optimal Planning Proficiency.” or “Leveraging Pre-trained Large Language Models to Construct and Utilize World Models for Model-based Task Planning.” seems to be to use LLMs to translate tasks to PDDL which stands for Planning Domain Definition Language. Then, have a solver/planner solve that PDDL problem. Below is an example.
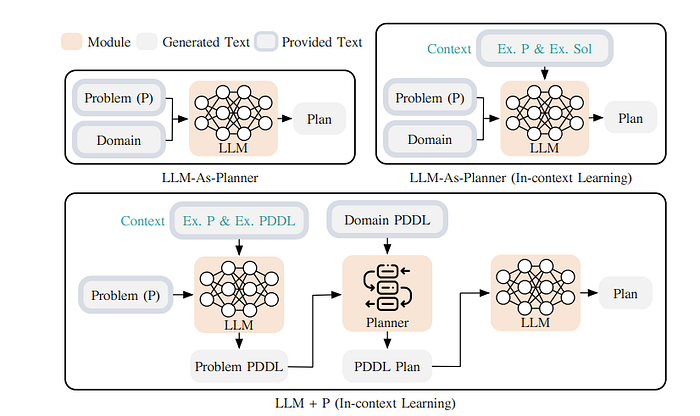
Now, this sounds good but what is PDDL and what are the limitations of it?
PDDL
According to here, PDDL acts a lot like logic where the formulation is
- Objects: Things in the world that interest us.
2. Predicates: Properties of objects that we are interested in; can be true or false.
3. Initial state: The state of the world that we start in.
4. Goal specification: Things that we want to be true.
5. Actions/Operators: Ways of changing the state of the world.
Now we can see how this can be used for planning but this can’t say have LLMs solving problems, like in pen-testing, where the predicates are not necessarily known, we do not have all the information for the initial state and the action space is extremely large.
So one question is can we do this while only using LLM instead?
SayCanPay: Heuristic Planning with Large Language Models using Learnable Domain Knowledge
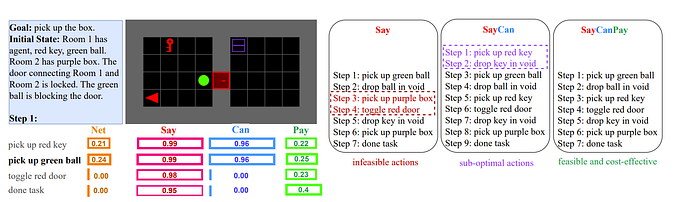
In “SayCanPay: Heuristic Planning with Large Language Models using Learnable Domain Knowledge” the idea is to, inspired by PDDL add heuristics to LLMs. To “generate actions (Say) guided by learnable domain knowledge, that evaluates actions’ feasibility (Can) and long-term reward/payoff (Pay), and heuristic search to select the best sequence of actions”. To be more specific, each stage generates a probability for the actions and then the probabilities are multiplied.
I don’t think the authors compared this method to the PDDL methods but I do think this gives a more general approach to large action space etc. But let’s say we want to add a bit of learning here where we hope the agent gets better from past mistakes. The first interesting paper here was “ExpeL: LLM Agents Are Experiential Learners”
ExpeL: LLM Agents Are Experiential Learners

The main idea of this paper is to learn from success/failure for the given task!
For this, the authors just
- generated a lot of ReAct-type models with failures/successes and then stored them in a database! Here, multiple trajectories are done for the exact same task.
- Then for a given task, the authors do RAG to get the most similar task and the successes and failures from it.
- Next, insight is drawn from the successes/failures to identify the best practices/what the task wants. The method the authors used here was pretty interesting where they have operations like ADD for adding an insight, EDIT for editing an insight, DOWNVOTE for disagreeing with an existing insight, and UPVOTE for agreeing with an existing insight. This is done for every new insight added
The authors explain the reason for this design is so that the insights are robust to invalid/misguided insights. Then, finally, we have an inference with the insights below!
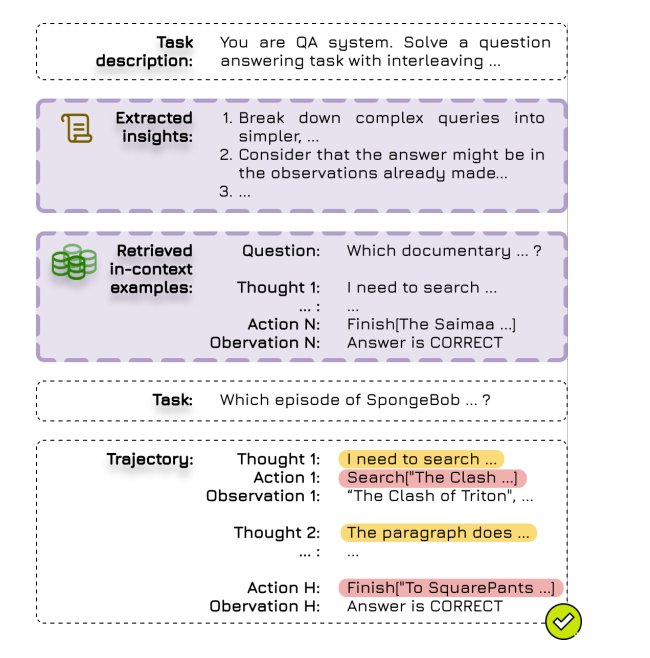
I think this is more promising. Even for pen-testing, if we have a database on what is good vs what is bad given the situation it may be useful. But I think the main interesting part of this paper was how the LLM worked with storing the insights. This can probably be expanded to make LLMs have a to-do list when faced with new information.
Now, another interesting class of research for planning is trying to integrate Monte Carlo Tree Search. Now what is Monte Carlo Tree Search?
Monte Carlo Tree Search

According to Wikipedia, Monte Carlo Tree Search has 4 stages
- Selection-Select one of the unexplored nodes(game states) to explore more
- Expansion-Do a valid move from that state/node
- Simulation-Complete a playout from that node until the game is decided. In alpha zero I think instead of doing a playout they have a value network predicting the probability of winning from the given state
- Backpropagation- The result is used to update the higher-up nodes to make the tree, overall, see which actions have the highest win rate!
Now, how do we select these nodes? For this UCT(Upper Confidence Bound) is used where we select the node with the highest value in the formula below.
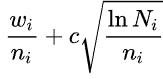
The wi stands for the number of wins while ni stands for the number of simulations done on the node so far. The c stands for some constant and Ni is the total number of simulations.
Now, what does this mean? For the first term, it gives the node with the highest win rate. In that if we win every simulation we do on that node, then that node is prioritized. This is called exploitation. This part is usually replaced with a value function for more complicated environments
The second node is the exploration term where if we are only doing a small amount of simulations vs the total amount of plays, we try to explore those nodes. So overall, this formula gives a trade-off between exploration and exploitation based on the constant c which is chosen empirically.
Now then how is this used for LLMs?
Language Agent Tree Search Unifies Reasoning, Acting, and Planning in Language Models
In “Language Agent Tree Search Unifies Reasoning, Acting, and Planning in Language Models”, the authors proposed LATS like below
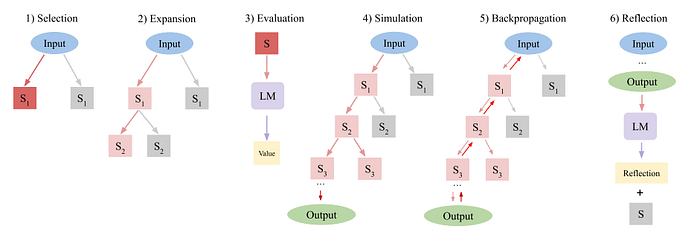
Here, the nodes in the LLM are the initial prompt x, the actions ais, and the observations ois like so

Here, the selection is the exact same but for the expansion n actions are done. Here, I think this means n actions in parallel from the same root node.
Evaluation is an interesting new step where for each new child node a new scalar value is assigned to it based on an evaluator. In this method, in particular, the LLM self generates this score. In addition, a self-consistency score is added. I think the idea for the self-consistency portion is they do self-consistency which is generated multiple times to get the majority opinion, and then get the probability. For this, I’m assuming the score is taken over the n actions. Finally, the score is calculated as
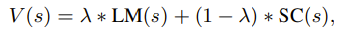
Simulation seems the exact same. For backpropagation, the value at node si is updated as
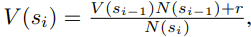
Where r is the reward.
Finally, in reflection, the authors, given the rewards and an unsuccessful terminal state, have the model provide a verbal self-reflection on why exactly it failed with alternatives which are stored in memory. Then RAG is used to provide context for future iterations for the agent and the value function.
Another interesting paper here is “Reason for Future, Act for Now: A Principled Framework for Autonomous LLM Agents with Provable Sample Efficiency” which seems pretty interesting which I might expand on here later on.
Now, finally, what are the current best approaches for iteratively updating a plan in the face of new information? For this, let’s start searching in “The Rise and Potential of Large Language Model Based Agents: A Survey” section 3.1.4, Planning.
ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models
The first idea seems like first generating a plan and executing it like “ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models” which
- First, a Planner makes a plan that is action+action input sequences
- Then the Worker executes each of the actions to get “Evidence”
- Finally, a solver combines the Planner and Worker to get the final answer.

This, interestingly seems to outperform ReAct. My understanding is this is because the LLM is doing less multitasking and focusing on one task which tends to work better in general.
Plan, Eliminate, and Track — Language Models are Good Teachers for Embodied Agents
Now, what if we want to go from high-level tasks and expand lower-level tracks while tracking whether we accomplished each task iteratively? This is done with “Plan, Eliminate, and Track — Language Models are Good Teachers for Embodied Agents.”
Here, first the planning module “translates a task description into a list of high-level sub-tasks”
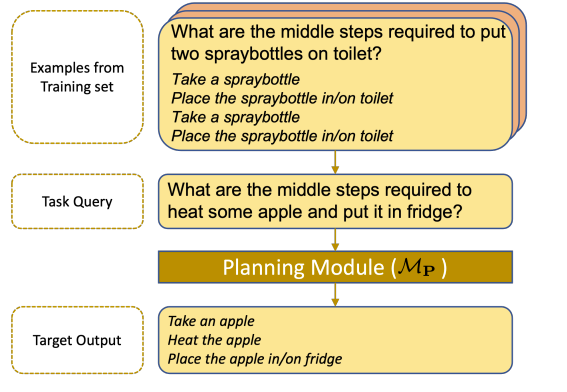
Then the Eliminate module eliminates unnecessary/irrelevant tasks

Finally, for the tracking module, given the actions we check if the task is completed
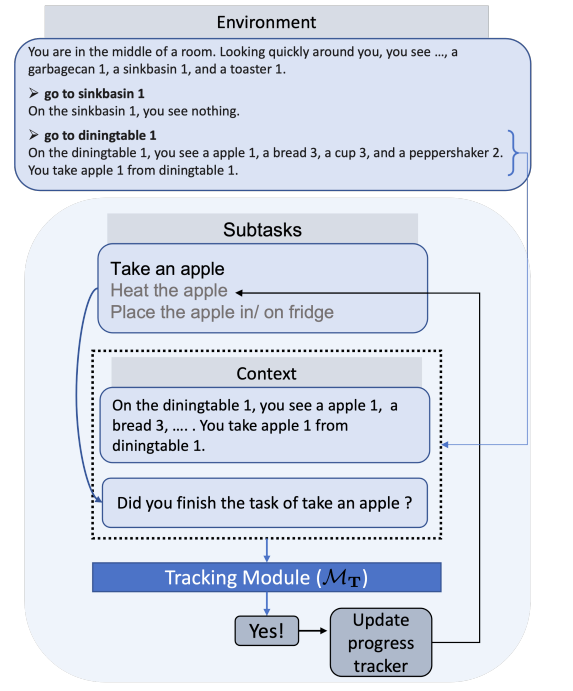
The main con of this tracking module is that it assumes that each task is independent in that if a certain task is finished it won’t mean any other task is finished from a given observation. But this may be assumed from the Eliminate module removing duplicate/overlapping tasks.
Now finally, one more interesting part is for choosing the next agent, the authors used attention to observation, action, and current task embeddings which I found pretty interesting. Here Ojs are the observations, ais are the actions and T is the task embedding

and then I think it’s trained on data. Overall it is an interesting idea on how to add in training into planning in addition to all the other components/modules.
Now, one idea some researchers had was whether we integrate responses from the environment/humans to make planning better. To answer this question, one interesting paper is “LLM-Planner: Few-Shot Grounded Planning for Embodied Agents with Large Language Models”
LLM-Planner: Few-Shot Grounded Planning for Embodied Agents with Large Language Models
The interesting part of this paper is we do iteratively update our plan but we have a high-level plan from an LLM planner that gets sent to a low-level planner where they both interact with each other in the face of new information like below
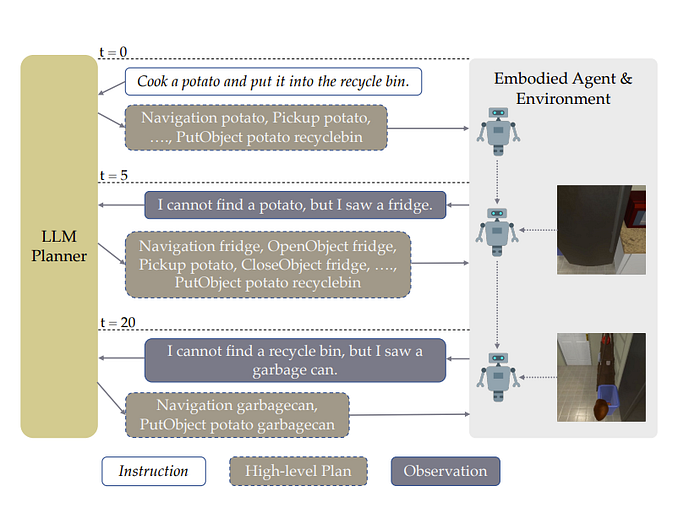
The code is here. By default, the idea seems to be just use in context learning and have the LLM Planner choose the next action like so
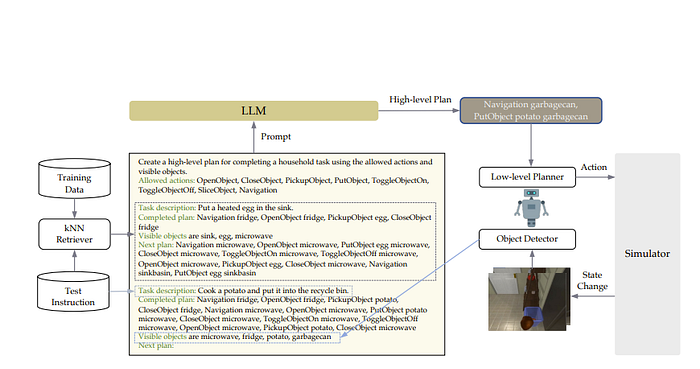
The interesting part is if it fails to execute an action, it seems to just remake a new plan with the added “visible objects”. In this way, it seems like having feedback is very important. Another interesting paper following this trend is “Explain, Plan and Select: Interactive Planning with Large Language Models Enables Open-World Multi-Task Agents”
Explain, Plan and Select: Interactive Planning with Large Language Models Enables Open-World Multi-Task Agents
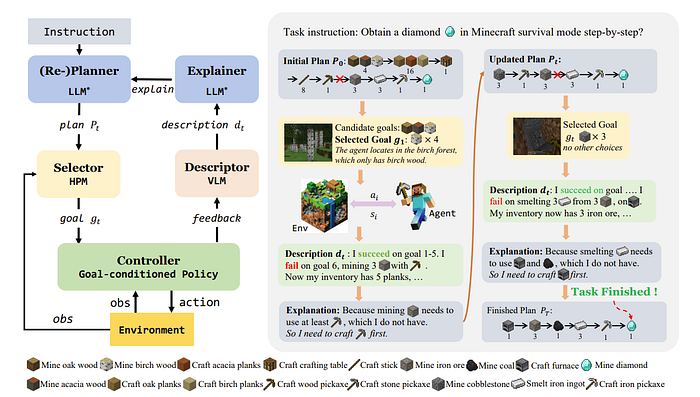
The authors are using agents for the task of doing Minecraft tasks. The main idea here is that in a complicated environment like Minecraft or any real-world environment in general, you tend to not be able to make a good plan from the start and feedback is necessary. In fact, here having the explainer explain the issue with the current plan and description while the planner replans seems to be the strategy.
Now one interesting aspect of this paper is the selector which selects the next goal that the goal-conditioned controller acts on. Here the goal-conditioned controller is just software to control Minecraft so we can think of the goal gt as an action we want to take.
Now, then how do we select an action in this paper? The paper finds that at least in the case of Minecraft
- “there often exist multiple feasible plans to complete a task”
- “despite the feasibility of all such plans, most of them are highly inefficient to execute in the current episode.” ex depending on the type of wood, you may not be able to obtain it efficiently.
- Some goals might not need sequential requirements/can be executed in any order
So the question is how do we execute a plan in the most efficient manner? To do this the authors made the problem predicting the nearest goal(ex collect birch wood) given the plan and the state from all the possible goals to execute.
To do this, the authors came up with a “horizon-predictive selector” that ranks each goal/action based on their feasibility/efficiency by predicting the number of timesteps to do the goal which we will call μ(given goal andd state), and then doing a softmax overall the negative μs for all feasible goals
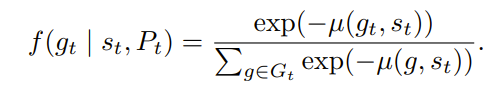
For the network, a pretty famous network called IMPALA CNN was used. My understanding is this allows for incredible distributed communication/training between workers like Minecraft agents and a centralized server.
For the code of the general logic, it can be found here.
Conclusion
Overall, I wasn’t able to find information in some questions I had like
- What’s the best way to represent/update a task list most places assume that just rearranging the current task list with feedback is the optimal method
- How best to integrate research/LLM searching external information. It seems like RAG is used for context from the start instead of say LLM searching by itself except for when the planning and evidence are separated in a paper.
But I do like that there is reinforcement learning combined with LLMs as it is more exciting than prompt engineering. Also, I did learn that feedback is pretty important. It is interesting though that not many papers combine MCTS with the feedback method etc. I may be missing a piece here.
